Kategorie
Kontakt
Vom Shopfloor zum Insight
Viele Industrieunternehmen starten mit einem klaren Ziel:
„Wir wollen unsere Shopfloor-Daten endlich in einem Dashboard sehen.“
Was danach oft passiert, ist immer gleich:
Ein BI-Tool wird ausgewählt, Maschinen angebunden, KPIs definiert. Das Dashboard existiert, doch die Entscheidungen im Betrieb verändern sich kaum.
Unsere Erfahrung bei Substring AG zeigt:
Dashboards scheitern selten an der Visualisierung.
Sie scheitern an fehlender Struktur davor.
Deshalb arbeiten wir mit einem klaren, wiederholbaren Ansatz, der Shopfloor-Daten systematisch in entscheidungsfähige Insights überführt.
Das Substring Shopfloor-to-Insight Framework
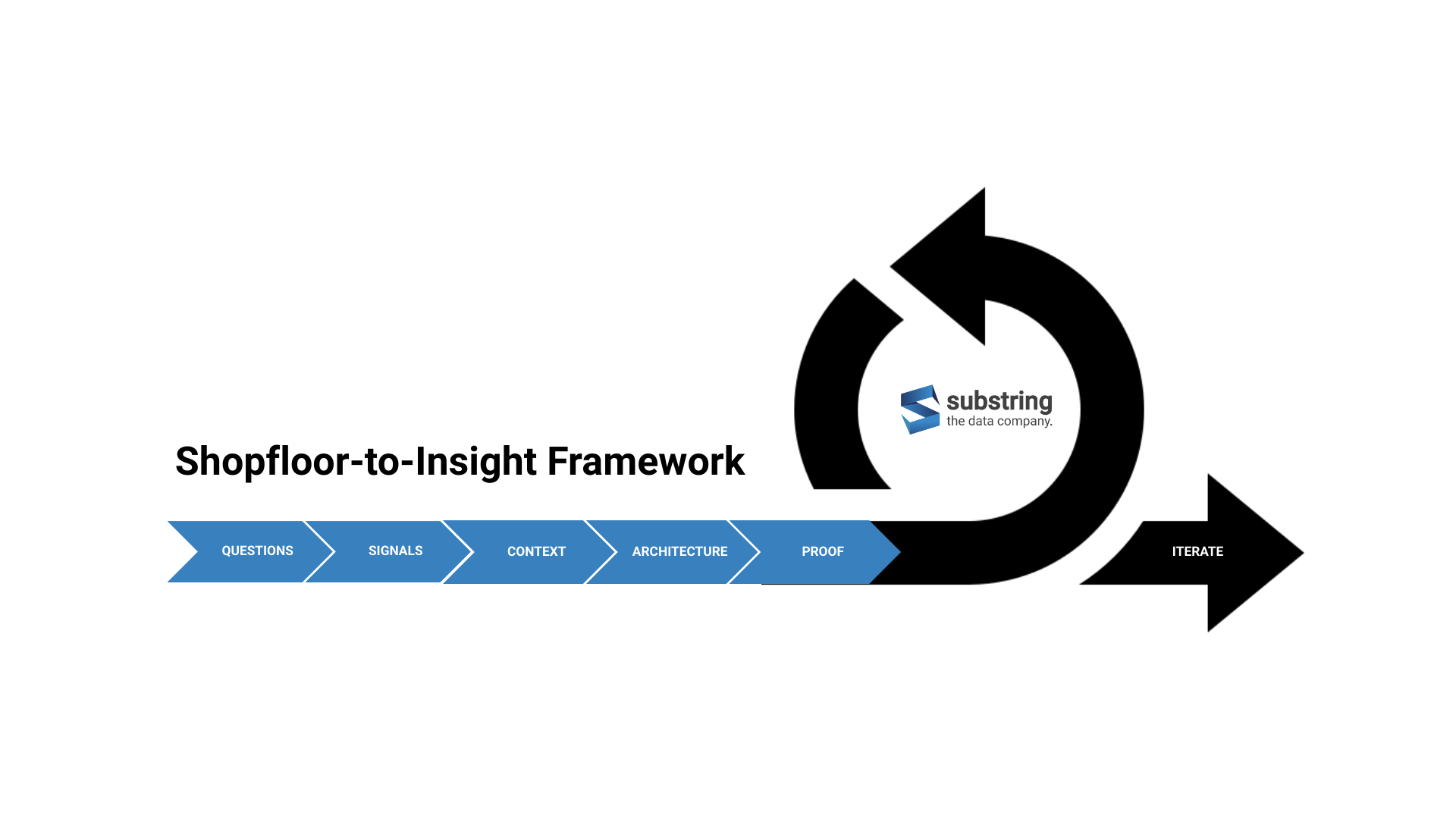
1) QUESTION: Entscheidungsfragen definieren
Der häufigste Fehler in Shopfloor-Analytics-Projekten ist, mit KPIs zu starten.
Die bessere Frage lautet:
- Welche Entscheidungen müssen im Betrieb täglich oder wöchentlich getroffen werden?
- Wer trifft diese Entscheidungen? Schichtleitung, Instandhaltung, Produktionsleitung?
- Was passiert heute konkret, wenn eine Abweichung sichtbar wird?
Das Ergebnis dieses Schritts sind konkrete Entscheidungsfragen, keine Metriken.
Beispiel:
"Welche Stillstände müssen wir heute priorisieren, um die Liefertreue nicht zu gefährden?"
Kennzahlen sind eine Ableitung, kein Startpunkt.
Im ersten Schritt erfassen wir in einem Workshop die wichtigsten Entscheidungsfragen.
2) SIGNALS: KPIs, Use Cases und relevante Signale identifizieren
Shopfloor-Systeme liefern enorme Datenmengen.
Nur ein kleiner Teil davon ist entscheidungsrelevant.
Typische relevante Signale sind:
- Maschinenzustände und Zustandswechsel
- Stillstands- und Störgründe
- Zykluszeiten und Taktabweichungen
- Qualitäts- oder Ausschusssignale
- Manuelle Inputs aus BDE oder Schichtnotizen
Mehr Sensoren bedeuten nicht automatisch bessere Insights.
Entscheidend ist die bewusste Auswahl der Signale, nicht deren Menge.
In diesem zweiten Schritt mappen wir die Kernfragen auf KPIs und diese auf Signale.
3) CONTEXT: Kontext & Datenmodellierung
Shopfloor-Daten benötigen Kontext:
- unterschiedliche Zeitachsen (Maschine, Auftrag, Schicht)
- Hierarchien (Werk → Linie → Maschine)
- saubere Trennung von Ereignissen und Zuständen
- Historisierung und Versionierung
In diesem Schritt definieren wir namentlich drei Dinge: Datenklassen, den Unified Namespace und die Payloads.
Datenklassen als Grundlage
Ein zentrales Element robuster Shopfloor-Datenmodelle ist die klare Trennung unterschiedlicher Datenklassen.
Nicht alle Daten verhalten sich gleich und sie sollten auch nicht gleich modelliert werden.
Typischerweise unterscheiden wir im industriellen Kontext diverse grundlegende Datenklassen:
- Signale (Measurements)
Kontinuierliche Messwerte wie Temperatur, Druck, Stromaufnahme oder Zykluszeit.
Sie verändern sich laufend, sind zeitabhängig und werden meist in hoher Frequenz erfasst. - Status (States)
Beschreiben den aktuellen Zustand eines Assets, z. B. Running, Idle, Stopped, Fault.
Status sind zeitlich gültig, bis sie sich ändern, und bilden die Basis für Auswertungen wie Verfügbarkeit oder OEE. - Events
Diskrete, zeitpunktbezogene Ereignisse wie Stillstandsgründe, Störmeldungen, Rüstbeginn oder Auftragswechsel.
Events liefern Kontext und Erklärung für Status- oder Signalveränderungen.
Diese Unterscheidung ist entscheidend für:
- korrekte Zeitaggregation
- saubere KPI-Berechnung
- konsistente Interpretation über verschiedene Dashboards hinweg
Ein Datenmodell, das Signale, Status und Events vermischt, führt zwangsläufig zu widersprüchlichen Ergebnissen.
Erst durch die bewusste Modellierung dieser Datenklassen entsteht ein stabiler, wiederverwendbarer Datenraum unabhängig vom konkreten Dashboard oder BI-Tool.
Unified Namespace als Struktur
Ein zentrales Element stabiler Shopfloor-Analytics ist eine einheitliche Strukturierung der Datenströme.
Genau hier setzt das Konzept des Unified Namespace (UNS) an.
Ein UNS definiert:
- eine klare, hierarchische Struktur für Produktionsdaten
- eine gemeinsame Semantik über Maschinen, Linien und Werke hinweg
- einen entkoppelten Datenraum zwischen OT und IT
Typische Ebenen im UNS:
- Enterprise / Site / Area
- Line / Cell / Machine
- Signals / Events / States
Statt Daten direkt für ein einzelnes Dashboard aufzubereiten, werden sie einmal sauber publiziert und können danach von unterschiedlichen Anwendungen genutzt werden. Eine saubere UNS-Struktur sorgt dafür, dass alle Datensätze jederzeit eindeutig rückverfolgbar bleiben und neue Maschinen, Linien oder Standorte nahtlos integriert werden können.
Payload Definition als Bedeutung
Ein häufiger Fehler in Shopfloor-Projekten ist, möglichst viele Rohdaten zu übertragen.
Das erzeugt Volumen, aber noch keinen Nutzen.
Eine saubere Payload Definition regelt:
- klare Feldnamen und Einheiten mit Kontext, damit Daten auch später noch auswertbar bleiben
- saubere Zeitstempel (Event Time vs. Processing Time, Datumsformat, Zeitzonen)
- Schemas pro Datenkategorie
- optionale Kontextfelder (Auftrag, Schicht, Produkt)
Beispiele:
- Zustandswechsel als Events
- Zykluszeiten als Messwerte
- Stillstandsgründe als klassifizierte Ereignisse
Ziel einer klaren Payload-Definition ist, dass jeder Datensatz eindeutig verständlich ist und alle notwendigen Kontextinformationen enthält, um korrekt interpretiert zu werden.
4) ARCHITECTURE: Datenarchitektur & Datenpipelines definieren
Erst wenn Entscheidungsfragen, Signale und Kontext klar sind, wird Technologie relevant.
Typische Fragen in diesem Schritt:
- Edge, OPC-UA, MQTT oder Historian?
- Streaming oder Batch?
- zentrale oder verteilte Architektur?
In industriellen Umgebungen übernimmt eine Shopfloor-Integrationsebene, oft bestehend aus SCADA-, Integration- und Historian-Systemen, eine zentrale Rolle.
Sie stellt sicher, dass Prozessdaten konsistent erfasst, zeitlich korrekt historisiert und für analytische Anwendungsfälle verfügbar gemacht werden.
Die konkrete Toolwahl ist austauschbar. Es geht um die Einführung von Konzepten, wie Data Lakes oder Data Warehouses.
Entscheidend ist eine Architektur, die robust, nachvollziehbar und erweiterbar ist.
In diesem Schritt entwickeln wir gemeinsam eine Architektur die funktioniert und den Bedürfnissen entsprechend dimensioniert ist.
5) PROOF: PoC für ein Dashboard (Proof of Value)
Jetzt wird sichtbar, ob die Vorarbeit trägt.
Der PoC ist kein finales Dashboard, sondern ein gezielter Realitätscheck:
- Führt das Datenmodell zu klaren Aussagen?
- Können echte Nutzer damit bessere Entscheidungen treffen?
- Funktioniert die Datenpipeline stabil genug für den Betrieb?
Typischer Umfang eines PoC:
- 1–2 klar abgegrenzte Use Cases (z. B. Stillstände, OEE, Durchsatz)
- wenige, fokussierte Dashboards
- reale Daten, inklusive Unschärfen und Lücken
- klare Definition, was als Mehrwert gilt
Was bewusst nicht Ziel des PoC ist:
- vollständige Abdeckung aller Maschinen
- perfekte Datenqualität überall
- ein universelles KPI-Dashboard für alle
Der PoC beweist nicht, dass ein Dashboard gebaut werden kann.
Er beweist, dass Daten tatsächlich zu besseren Entscheidungen führen und die Daten im Kontext richtig interpretiert werden.
6) ITERATE: Iteration, Lernen & Ausbau (Use Case für Use Case)
Erst nach dem PoC beginnt die eigentliche Arbeit.
Analytics ist kein einmaliges Projekt, sondern ein lernender Prozess:
- Welche Annahmen waren richtig?
- Wo fehlt Kontext?
- Welche Fragen sind neu entstanden?
Typische nächste Schritte:
- Skalierung: gleiche Logik auf weitere Linien, Maschinen oder Werke
- Neue Use Cases: Qualität, Energie, Wartung, Materialfluss
- Vertiefte Analysen: Ursachen, Engpässe, Prozessstabilität
- Optimierung: datenbasierte Verbesserungen im Betrieb
- Advanced Analytics (wo sinnvoll): Prognosen, Anomalien, Predictive Maintenance
Wichtig dabei:
- klare Priorisierung der Use Cases
- ein gepflegter Analytics-Backlog
- Ownership im Betrieb
- kontinuierliche Arbeit an Datenqualität
Technische Lösungen entfalten ihren Nutzen nur dann, wenn sie von den Anwendern im Betrieb getragen werden. Die Einbindung der relevanten Stakeholder und die Anpassung bestehender Arbeitsweisen sind daher ein wesentlicher Erfolgsfaktor.
Der eigentliche Wert entsteht nicht mit dem ersten Dashboard.
Er entsteht, wenn jeder weitere Use Case schneller, günstiger und besser umgesetzt werden kann als der erste.