Kategorie
Kontakt
Open-Source-Datenarchitektur für Unternehmen
Microsoft Fabric, Databricks, Snowflake – die meisten Unternehmen denken bei «Datenplattform» sofort an kommerzielle Produkte. Diese Lösungen haben ihre Berechtigung: Sie sind schnell aufgesetzt, gut integriert und kommen mit Support. Aber sie haben einen Preis – und zwar nicht nur in Franken. Jede Plattformwahl ist eine Architekturentscheidung. Und jede kommerzielle Plattform bindet Sie an einen Anbieter, dessen Preismodell sich ändern kann, dessen Roadmap Sie nicht kontrollieren und dessen Datenformate möglicherweise proprietär sind.
Es gibt eine Alternative: eine vollständige Datenplattform aus Open-Source-Komponenten. Kein einzelnes Produkt, sondern ein zusammengesetzter Stack, bei dem jede Schicht unabhängig austauschbar ist. Dieser Artikel beschreibt eine praxiserprobte Referenzarchitektur – Schicht für Schicht – und zeigt, wann der Open-Source-Weg sinnvoll ist und wann nicht.
Die Referenzarchitektur im Überblick
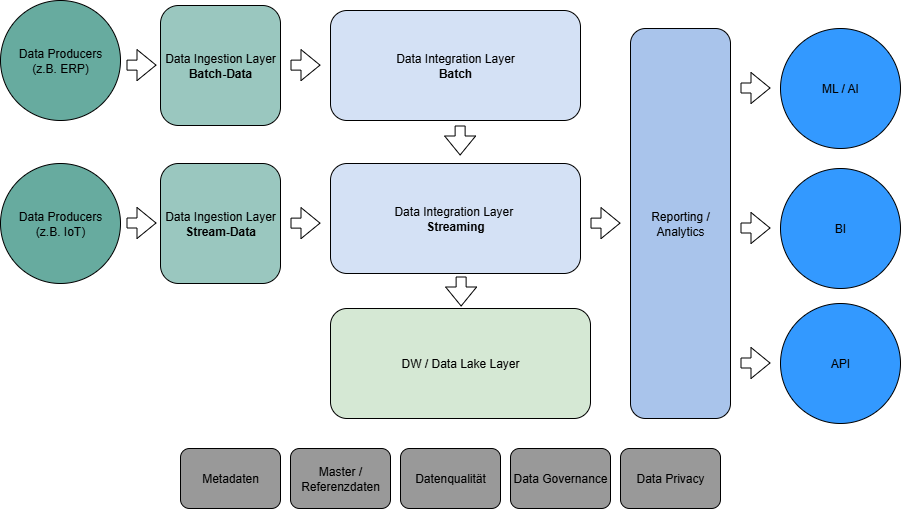
Eine Open-Source-Datenarchitektur folgt denselben Prinzipien wie kommerzielle Plattformen: Daten werden aus Quellsystemen extrahiert, transformiert, gespeichert und für Analyse bereitgestellt. Der Unterschied liegt darin, dass jede Schicht durch ein eigenständiges Open-Source-Projekt abgedeckt wird – ohne dass ein einzelner Anbieter den gesamten Stack kontrolliert.
Die sechs Schichten:
1. Data Producers – die Quellsysteme (ERP, IoT-Sensoren, Datenbanken, APIs)
2. Data Ingestion Layer – Daten einsammeln, sowohl Batch als auch Streaming
3. Data Integration Layer – Orchestrierung und Transformation (ETL/ELT)
4. DW / Data Lake Layer – zentraler Speicher mit Tabellenformat und Query Engine
5. Reporting & Analytics – Dashboards und Self-Service-BI
6. Governance Layer – Datenkatalog, Metadaten, Datenqualität, Privacy
Zusätzlich konsumieren nachgelagerte Systeme die Daten: ML/AI-Plattformen, APIs für operative Systeme und Business Intelligence-Tools.
Schicht 1: Data Producers – dort, wo die Daten entstehen
Die Quellsysteme sind in der Regel nicht Open Source – sie sind das, was das Unternehmen bereits hat: SAP, Microsoft Dynamics, Salesforce, Messsysteme (MES), IoT-Gateways, relationale Datenbanken. In Industrieunternehmen kommen oft OPC-UA- oder MQTT-Streams von Maschinen dazu; im öffentlichen Verkehr sind es Fahrplandaten, Fahrgastzählungen und Sensordaten von Schienenfahrzeugen.
Die Architektur muss zwei Datentypen verarbeiten: Batch-Daten (tägliche Exporte aus dem ERP, CSV-Dateien, Datenbank-Snapshots) und Stream-Daten (Echtzeit-Events von Sensoren, Log-Streams, Change Data Capture aus Datenbanken).
Schicht 2: Data Ingestion – Apache NiFi für den Datentransport
Das Problem: Daten aus Dutzenden Quellen müssen zuverlässig, nachvollziehbar und ohne Datenverlust in die Datenplattform transportiert werden. Manche liefern Dateien per SFTP, andere bieten REST-APIs, wieder andere schreiben in Message Queues.
Die Lösung: Apache NiFi.
NiFi ist ein visuelles Datenfluss-Tool, das Daten zwischen Systemen transportiert – ohne Code schreiben zu müssen. Es bietet über 300 Prozessoren für verschiedene Protokolle und Formate: SFTP, HTTP, JDBC, Kafka, MQTT, OPC-UA, S3-kompatibel und viele mehr.
Warum NiFi und nicht einfach ein Python-Skript? Weil NiFi Data Provenance bietet: Für jedes einzelne Datenpaket wird aufgezeichnet, woher es kam, wann es verarbeitet wurde und wohin es ging. Das ist für regulierte Branchen (öffentliche Verwaltung, Gesundheitswesen) ein entscheidender Vorteil. Ausserdem bietet NiFi Backpressure-Management: Wenn ein nachgelagertes System überlastet ist, hält NiFi die Daten zurück, statt sie zu verlieren.
Für Streaming-Daten übernimmt Apache Kafka oder ein leichtgewichtiger MQTT-Broker die Rolle des Ingestion Layers. NiFi kann auch hier als Brücke fungieren – es nimmt Streaming-Daten entgegen und schreibt sie in Kafka oder direkt in den Data Lake.
Praxis-Tipp: Kombinieren Sie NiFi für heterogene Quellen (ERP-Exporte, Dateien, APIs) mit Kafka für Event-Streaming (Sensordaten, CDC). NiFi ist stark im «letzten Meter» – also dort, wo die Quelle kein Standard-Protokoll spricht.
Schicht 3: Data Integration – Apache Airflow + dbt
Sobald die Daten in der Plattform sind, müssen sie orchestriert und transformiert werden. Hier kommen zwei Tools zum Einsatz, die sich ideal ergänzen:
Apache Airflow – der Orchestrator
Airflow plant, startet und überwacht Workflows (DAGs – Directed Acyclic Graphs). Es beantwortet die Frage: In welcher Reihenfolge, wann und unter welchen Bedingungen sollen Datenjobs laufen?
Typische Aufgaben: «Jeden Morgen um 06:00 die ERP-Daten laden, dann die dbt-Transformation starten, dann den Qualitätscheck ausführen, dann den Report aktualisieren.» Wenn ein Schritt fehlschlägt, benachrichtigt Airflow das Team und blockiert die nachfolgenden Schritte.
Airflow ist der De-facto-Standard für Batch-Orchestrierung in der Data-Engineering-Welt – mit einer riesigen Community und Hunderten von vordefinierten Operatoren (für Datenbanken, Cloud-Services, APIs).
dbt (Data Build Tool) – der Transformator
dbt transformiert Daten mit SQL – und bringt Software-Engineering-Praktiken in die Datenwelt: Versionierung (Git), Testing, Dokumentation und Modularität.
Im Open-Source-Stack arbeitet dbt gegen das Data Warehouse / Lakehouse – typischerweise über den Trino-Adapter. Die Transformationslogik folgt der Bronze-Silber-Gold-Architektur: Rohdaten (Bronze) → bereinigte Daten (Silber) → geschäftsfertige Modelle (Gold).
Die Arbeitsteilung: Airflow orchestriert wann und in welcher Reihenfolge. dbt definiert was transformiert wird und wie. Diese Trennung macht den Stack wartbar: Transformationslogik in dbt ist SQL, lesbar und testbar. Orchestrierungslogik in Airflow ist Python, flexibel und erweiterbar.
Schicht 4: DW / Data Lake Layer – MinIO, Apache Iceberg, Trino
Das Herzstück der Architektur. Hier werden Daten dauerhaft gespeichert, strukturiert und für Abfragen bereitgestellt. Im Open-Source-Stack übernehmen drei Komponenten diese Aufgabe:
MinIO – der Objektspeicher
MinIO ist ein S3-kompatibler Objektspeicher, der on-premise oder in einer privaten Cloud betrieben werden kann. Er speichert die eigentlichen Datendateien (Parquet, ORC, CSV) – genau wie Amazon S3 in der Cloud, aber ohne Abhängigkeit von einem Cloud-Anbieter.
Warum nicht einfach eine Festplatte? Weil MinIO horizontal skaliert: mehr Knoten = mehr Speicher und mehr Durchsatz. Es bietet Erasure Coding für Ausfallsicherheit, Verschlüsselung at rest und eine S3-kompatible API, die alle gängigen Tools verstehen.
Für Unternehmen mit Datensouveränitäts-Anforderungen (öffentliche Verwaltung, regulierte Branchen) ist MinIO besonders attraktiv: Die Daten verlassen nie das eigene Rechenzentrum, und es gibt keine Abhängigkeit von einem Cloud-Provider.
Apache Iceberg – das Tabellenformat
Iceberg ist das entscheidende Puzzleteil, das einen Data Lake in ein Lakehouse verwandelt. Es definiert, wie Datendateien in MinIO zu logischen Tabellen organisiert werden – mit Eigenschaften, die man bisher nur von Data Warehouses kannte:
ACID-Transaktionen: Parallele Lese- und Schreibvorgänge sind sicher – keine korrupten Daten, auch wenn mehrere Prozesse gleichzeitig schreiben.
Schema-Evolution: Spalten hinzufügen, umbenennen oder entfernen – ohne Milliarden von Zeilen neu schreiben zu müssen.
Time Travel: Jede Änderung erzeugt einen Snapshot. Sie können jederzeit den Zustand einer Tabelle zu einem beliebigen Zeitpunkt abfragen – ideal für Audits, Debugging und Compliance.
Hidden Partitioning: Iceberg optimiert die Datenpartitionierung automatisch. Abfragen scannen nur die relevanten Dateien – das beschleunigt Queries massiv.
Multi-Engine-Kompatibilität: Trino, Spark, Flink und Presto können alle auf denselben Iceberg-Tabellen arbeiten – gleichzeitig und konsistent. Das ist der grösste Vorteil gegenüber proprietären Formaten.
Trino – die SQL-Query-Engine
Trino (ehemals PrestoSQL, entwickelt bei Facebook) ist eine verteilte SQL-Engine, die Daten dort abfragt, wo sie liegen – ohne sie kopieren zu müssen. In unserer Architektur liest Trino die Iceberg-Tabellen auf MinIO und stellt sie per Standard-SQL zur Verfügung.
Warum Trino und nicht einfach eine Datenbank? Weil Trino Storage und Compute trennt. Der Speicher (MinIO) skaliert unabhängig von der Rechenleistung (Trino-Worker). Sie zahlen nicht für Compute, wenn niemand Abfragen stellt. Und Trino kann gleichzeitig auf mehrere Datenquellen zugreifen – Iceberg-Tabellen, PostgreSQL-Datenbanken, Kafka-Streams – alles in einem einzigen SQL-Query.
Praxis-Tipp: Für interaktive Abfragen (BI, Ad-hoc-Analyse) ist Trino ideal. Für schwere Batch-Verarbeitungen (Millionen Zeilen transformieren) kann Apache Spark als zusätzliche Engine hinzugefügt werden – beide arbeiten auf denselben Iceberg-Tabellen.
Schicht 5: Reporting & Analytics – Apache Superset
Das Problem: Die Daten sind sauber, strukturiert und in Iceberg-Tabellen verfügbar – aber die Fachabteilung braucht Dashboards, nicht SQL.
Die Lösung: Apache Superset.
Superset ist ein Open-Source-BI-Tool, das direkt auf Trino (oder andere SQL-Engines) zugreift und interaktive Dashboards bereitstellt. Es unterstützt Dutzende Visualisierungstypen, rollenbasierte Zugriffskontrolle, SQL-Editor für Power User und einen No-Code-Dashboard-Builder für Fachbereiche.
Superset vs. Power BI – die ehrliche Einordnung:
Superset ist leistungsfähig und flexibel, hat aber nicht den Poliergrad von Power BI oder Tableau. Die Stärken liegen im Self-Service-SQL, in der nativen Integration mit dem Open-Source-Stack und in den fehlenden Lizenzkosten. Die Schwächen: weniger vorgefertigte Visuals, kein nativer Mobile-Client, steilere Lernkurve für Nicht-Techniker.
Wann Superset, wann Power BI? Wenn Ihr Unternehmen bereits im Microsoft-Ökosystem arbeitet (Azure, M365, Dynamics), ist Power BI oft die pragmatischere Wahl. Wenn Sie auf Unabhängigkeit setzen, On-Premise bleiben müssen oder ein technisch versiertes Team haben, ist Superset eine echte Alternative.
Neben Superset gibt es weitere Open-Source-BI-Optionen: Metabase (einfacher, weniger SQL-fokussiert), Redash (SQL-zentriert, leichtgewichtig) und Grafana (stark für Monitoring und Zeitreihen, weniger für klassische BI).
Schicht 6: Governance – der oft vergessene Unterbau
Eine Datenplattform ohne Governance wird zum Data Swamp. Im Open-Source-Stack sind die Governance-Komponenten eigenständige Projekte:
Datenkatalog / Dateninventar: Apache Atlas oder DataHub (LinkedIn Open Source) – sie dokumentieren, welche Tabellen existieren, wer sie besitzt, welche Daten sie enthalten und wie sie verknüpft sind. Vergleichbar mit einer Datenlandkarte in digitaler Form.
Metadaten-Management: Iceberg speichert technische Metadaten (Schema, Partitionierung, Snapshots) nativ. Für fachliche Metadaten (Beschreibungen, KPI-Definitionen) ergänzen Datenkatalog-Tools die Lücke.
Datenqualität: Great Expectations oder dbt Tests – automatisierte Prüfungen, die bei jedem Pipeline-Lauf Datenqualitätsregeln validieren: «Sind alle Pflichtfelder gefüllt? Liegt der Wert im erwarteten Bereich? Gibt es Duplikate?»
Master- / Referenzdaten: Zentrale Verwaltung von Stammdaten (Kunden, Produkte, Standorte) – oft in einer separaten Datenbank, die als «Single Source of Truth» dient und in den Data Lake integriert wird.
Data Privacy: Apache Ranger für feingranulare Zugriffskontrolle (Zeilen-, Spalten-Level). Besonders relevant für Unternehmen in der öffentlichen Verwaltung, die dem neuen Schweizer DSG oder der EU-DSGVO unterliegen.
Wann Open Source – und wann nicht?
Die Entscheidung ist keine Glaubensfrage. Sie hängt von konkreten Faktoren ab:
Open Source ist die bessere Wahl, wenn:
Datensouveränität kritisch ist. Öffentliche Verwaltungen, Gesundheitswesen, Verteidigungsbranche – überall, wo Daten das eigene Rechenzentrum nicht verlassen dürfen. MinIO + Iceberg + Trino laufen vollständig on-premise, ohne Cloud-Abhängigkeit.
Vendor Lock-in vermieden werden soll. Jede Komponente ist austauschbar: Trino kann durch Spark ersetzt werden. MinIO durch S3. Iceberg ist ein offenes Tabellenformat, das Dutzende Engines lesen können. Sie sind nie an einen Anbieter gebunden.
Lizenzkosten ein Problem sind. Kein Pay-per-Query, kein Pay-per-User, kein plötzlicher Preisanstieg. Die Software ist frei. Kosten entstehen für Infrastruktur (Server, Storage) und Personal (Betrieb, Entwicklung).
Technisches Know-how vorhanden ist. Ein internes oder externes Data-Engineering-Team, das Linux, Docker, SQL und Python beherrscht, kann diesen Stack produktiv betreiben.
Flexibilität wichtiger ist als Komfort. Der Open-Source-Stack ist modular – jede Komponente kann unabhängig skaliert, ausgetauscht oder erweitert werden. Das gibt Freiheit, erfordert aber Entscheidungen.
Eine kommerzielle Plattform ist die bessere Wahl, wenn:
Geschwindigkeit zählt. Microsoft Fabric oder Databricks sind in Tagen produktiv. Ein Open-Source-Stack braucht Wochen bis Monate für Setup, Integration und Härtung.
Kein dediziertes Data-Engineering-Team existiert. Ohne Personen, die Airflow-DAGs schreiben, Trino konfigurieren und MinIO betreiben können, wird der Open-Source-Weg teuer.
Microsoft-Ökosystem bereits im Einsatz ist. Wenn Power BI, Azure, M365 und Dynamics bereits lizenziert sind, ist Fabric der natürliche nächste Schritt – die Integration ist nahtlos.
SLA und Support entscheidend sind. Kommerzielle Plattformen bieten garantierte Verfügbarkeit und einen Ansprechpartner bei Problemen. Im Open-Source-Stack sind Sie auf Community, Dokumentation und eigenes Know-how angewiesen.
Hybride Ansätze – das Beste aus beiden Welten
In der Praxis sehen wir häufig hybride Architekturen:
Open-Source-Kern + kommerzielles BI: Iceberg + MinIO + Trino für Speicher und Compute – aber Power BI als Frontend, weil die Fachabteilung es bereits kennt. Trino bietet einen ODBC/JDBC-Connector, den Power BI direkt ansprechen kann.
Open-Source-Ingestion + kommerzielle Plattform: NiFi für die heterogene Datensammlung (ERP, MES, IoT) – aber Fabric oder Databricks als zentrales Lakehouse. NiFi transportiert die Daten, die Plattform verarbeitet sie.
Cloud-Storage + Open-Source-Compute: Daten liegen auf Azure Blob Storage oder AWS S3 – aber Iceberg als offenes Tabellenformat und Trino als Query-Engine. Kein Vendor Lock-in auf Compute-Ebene, aber Cloud-Skalierung für Storage.
Der Stack in der Praxis – drei Szenarien
Szenario 1: Mittelständischer Industriebetrieb (on-premise)
Ein Maschinenbauunternehmen mit 500 Mitarbeitenden, eigenem Rechenzentrum, SAP als ERP und Siemens-Sensorik an den Produktionslinien. Datensouveränität ist wichtig (Kundendaten, Konstruktionsdaten).
Stack: NiFi (ERP-Export + OPC-UA-Sensordaten) → Airflow + dbt (Bronze-Silber-Gold) → MinIO + Iceberg + Trino (Lakehouse) → Superset (Dashboards) + Python/Jupyter (Data Science)
Vorteil: Keine Cloud-Abhängigkeit, keine Lizenzkosten, volle Kontrolle. Betrieb auf drei Linux-Servern oder einer Kubernetes-Plattform.
Szenario 2: Kantonale Verwaltung (Datensouveränität)
Eine kantonale Verwaltung, die Open Government Data publizieren und intern Data-Driven arbeiten will – aber Daten dürfen die Schweiz nicht verlassen.
Stack: NiFi (Daten aus Fachapplikationen) → Airflow + dbt → MinIO + Iceberg + Trino (Schweizer Rechenzentrum) → Superset (interne Dashboards) + API-Layer (Open Data Portal)
Vorteil: rDSG-konform, kein Cloud Act-Risiko, vollständig in Schweizer Infrastruktur. Metadaten und Datenkatalog mit DataHub.
Szenario 3: Startup / Scale-up (Cloud-nativ)
Ein datengetriebenes Startup, das schnell skalieren muss und keine grossen Lizenzbudgets hat.
Stack: NiFi oder Airbyte (SaaS-Quellen) → Airflow (managed auf Azure) → Iceberg auf S3 → Trino (managed auf Azure) → Superset (self-hosted auf Azure)
Vorteil: Skaliert mit dem Business, keine Lock-in-Risiken, Kosten wachsen proportional zum Datenvolumen.
So starten Sie – der pragmatische Weg
Schritt 1: Evaluieren, nicht dogmatisch entscheiden. Nicht jedes Unternehmen braucht den vollständigen Open-Source-Stack. Erstellen Sie eine Datenlandkarte und eine Datenstrategie – daraus ergibt sich, welche Architektur zu Ihren Anforderungen passt.
Schritt 2: Klein starten. Ein einzelner Use Case – etwa ein OEE-Dashboard auf Basis von Maschinendaten – reicht, um den Stack zu validieren. Docker Compose genügt für den Proof of Concept: NiFi + Airflow + dbt + MinIO + Iceberg + Trino + Superset laufen auf einem einzigen Server.
Schritt 3: Betrieb planen. Open Source ist kostenlos, aber nicht gratis. Planen Sie Aufwand für Monitoring (Prometheus + Grafana), Backups, Updates und Troubleshooting ein. Oder arbeiten Sie mit einem Partner, der den Stack kennt.
Schritt 4: Skalieren. Vom Docker-Compose-Setup auf Kubernetes migrieren, wenn das Datenvolumen wächst. Trino-Worker horizontal skalieren. MinIO-Cluster erweitern. Airflow auf CeleryExecutor umstellen.
Wie Substring Sie unterstützt
Substring arbeitet sowohl mit kommerziellen Plattformen (Microsoft Fabric, Power BI, Azure) als auch mit Open-Source-Stacks. Wir beraten technologieneutral – die Architektur folgt dem Bedarf, nicht einer Produktstrategie.
- Beratung und Strategie: Datenlandkarte, Datenstrategie, Architektur-Evaluation (Open Source vs. kommerziell vs. hybrid)
- Datenplattform: Setup und Betrieb von NiFi, Airflow, dbt, Iceberg, Trino, MinIO – oder Microsoft Fabric, je nach Kontext
- Data Engineering: Data Pipelines, Bronze-Silber-Gold, Datenmodellierung, Testing
- Künstliche Intelligenz: ML/AI auf dem Open-Source-Stack mit Spark, MLflow, Jupyter – oder Azure ML
- Schulung: Workshops zu dbt, Airflow, Iceberg für Ihr Data Team
→ Kontakt aufnehmen – wir helfen Ihnen, die richtige Architekturentscheidung zu treffen.
Weiterführende Glossar-Artikel
- Was ist ein Data Lake? – Bronze-Silber-Gold-Architektur erklärt
- Was ist eine Data Pipeline? – Datenfluss von Quelle zu Ziel
- dbt und Microsoft Fabric – dbt im kommerziellen Stack
- Microsoft Fabric für Industrieunternehmen – die kommerzielle Alternative
- Power BI Best Practices für die Industrie – BI unabhängig vom Stack
- Data Governance – Spielregeln für Daten
- Manufacturing Data Architecture – Referenzarchitektur für die Industrie
- Was ist Data Science? – ML/AI auf der Datenplattform
- Was ist MLOps? – Modelle in Produktion betreiben
- Was ist Generative AI? – LLMs und ihre Rolle im Stack
- Was ist RAG? – Retrieval Augmented Generation auf eigenen Daten
- Datenstrategie erstellen – der erste Schritt
- Datenlandkarte erstellen – Überblick über Ihre Datenlandschaft