Kategorie
Kontakt
Datenprojekt starten: Leitfaden Schweiz
"Wir müssen etwas mit unseren Daten machen"
Dieser Satz fällt in fast jedem Erstgespräch, das wir führen. Manchmal kommt er aus der Geschäftsleitung, die nach einem Branchenevent von Data-Driven Decision-Making gehört hat. Manchmal von der IT-Abteilung, die seit Jahren Excel-Reports verschickt und weiss, dass es besser geht. Und manchmal von einem Produktionsleiter, der nach dem dritten ungeplanten Maschinenstillstand sagt: "Das hätten wir doch sehen müssen."
Alle drei Ausgangspunkte sind valide. Aber sie erfordern ein unterschiedliches Vorgehen:
Top-Down: Die Geschäftsleitung will eine Datenstrategie. Grosses Bild, Vision, Roadmap. Risiko: Viel Papier, wenig Wirkung.
Bottom-Up: Ein Fachbereich hat ein konkretes Problem und will eine schnelle Lösung. Risiko: Insellösung, die nicht skaliert.
Der pragmatische Mittelweg – und das ist der Ansatz, den wir bei Substring verfolgen – kombiniert beides: Eine klare Vision als Kompass, aber sofortige Umsetzung an einem konkreten, messbaren Use Case. Strategie und Execution parallel, nicht nacheinander.
Wie das in der Praxis funktioniert, zeigen wir in diesem Leitfaden.
Fünf Gründe, warum Datenprojekte scheitern
Bevor wir über das richtige Vorgehen sprechen, lohnt sich ein Blick auf die häufigsten Fehler. Nicht als Abschreckung, sondern weil jeder dieser Fehler vermeidbar ist – wenn man ihn kennt.
1. Zu gross starten
"Wir bauen ein unternehmensweites Data Warehouse mit allen Datenquellen." Klingt ambitioniert, endet aber regelmässig nach 18 Monaten ohne verwertbares Ergebnis. Besser: Mit einem abgegrenzten Use Case starten, der in Wochen statt Jahren einen messbaren Nutzen liefert. Die Plattform wächst dann organisch mit jedem weiteren Use Case.
2. Kein Business-Sponsor
Wenn ein Datenprojekt nur von der IT getrieben wird, fehlt die entscheidende Frage: "Welches Geschäftsproblem lösen wir?" Ohne einen Sponsor aus dem Business – jemanden, der die Ergebnisse tatsächlich nutzt und einfordert – werden selbst technisch brillante Lösungen zu Shelfware. Ein dedizierter Product Owner auf Kundenseite ist keine optionale Rolle, sondern eine Voraussetzung für den Projekterfolg.
3. Datenqualität wird unterschätzt
"Die Daten haben wir ja im ERP." Ja, aber in welcher Qualität? Fehlende Einträge, inkonsistente Formate, Duplikate, veraltete Stammdaten – in fast jedem Projekt verbringen wir 40–60% der Zeit mit Datenbereinigung und -integration. Wer das nicht einplant, wird vom Zeitplan überrollt. Data Governance ist kein Bürokratie-Überbau, sondern die Grundlage für verwertbare Ergebnisse.
4. Technologie vor Fragestellung
"Wir brauchen einen Data Lake." Wirklich? Oder brauchen Sie erst mal ein sauberes Reporting? Die Technologieentscheidung sollte sich aus dem Anwendungsfall ableiten, nicht umgekehrt. Ob Data Warehouse, Lakehouse oder eine hybride Architektur die richtige Wahl ist, hängt von Ihren Daten, Ihren Fragen und Ihrer bestehenden Infrastruktur ab.
5. Kein Plan für Tag 2
Das Dashboard ist live, das Modell deployed – fertig? Leider nein. Wer betreibt die Lösung, wenn sich das Quellsystem ändert? Wer überwacht die Datenqualität? Wer schult neue Mitarbeitende? Die Betriebsphase wird in der Projektplanung fast immer unterschätzt. Dabei entscheidet sie darüber, ob die Investition langfristig Wirkung zeigt.
Wo stehen Sie? Datenmaturität als Startpunkt
Bevor man ein Projekt definiert, muss man wissen, wo man steht. Nicht jede Organisation braucht Machine Learning – manche brauchen erst mal saubere Stammdaten und ein zentrales Reporting. Unsere Datenmaturitätsanalyse hilft, die eigene Ausgangslage realistisch einzuschätzen.
Ein Datenprojekt bewegt sich dabei immer auf zwei Ebenen gleichzeitig: dem Business-Kontext (Was wollen wir erreichen? Wie organisieren wir uns? Wie schaffen wir Datenkompetenz?) und dem technischen Kontext (Welche Architektur brauchen wir? Welche Plattform? Welche Analytik?). Beide Stränge müssen parallel entwickelt werden – sonst entsteht entweder eine Strategie ohne Umsetzung oder eine Technologie ohne Nutzen.
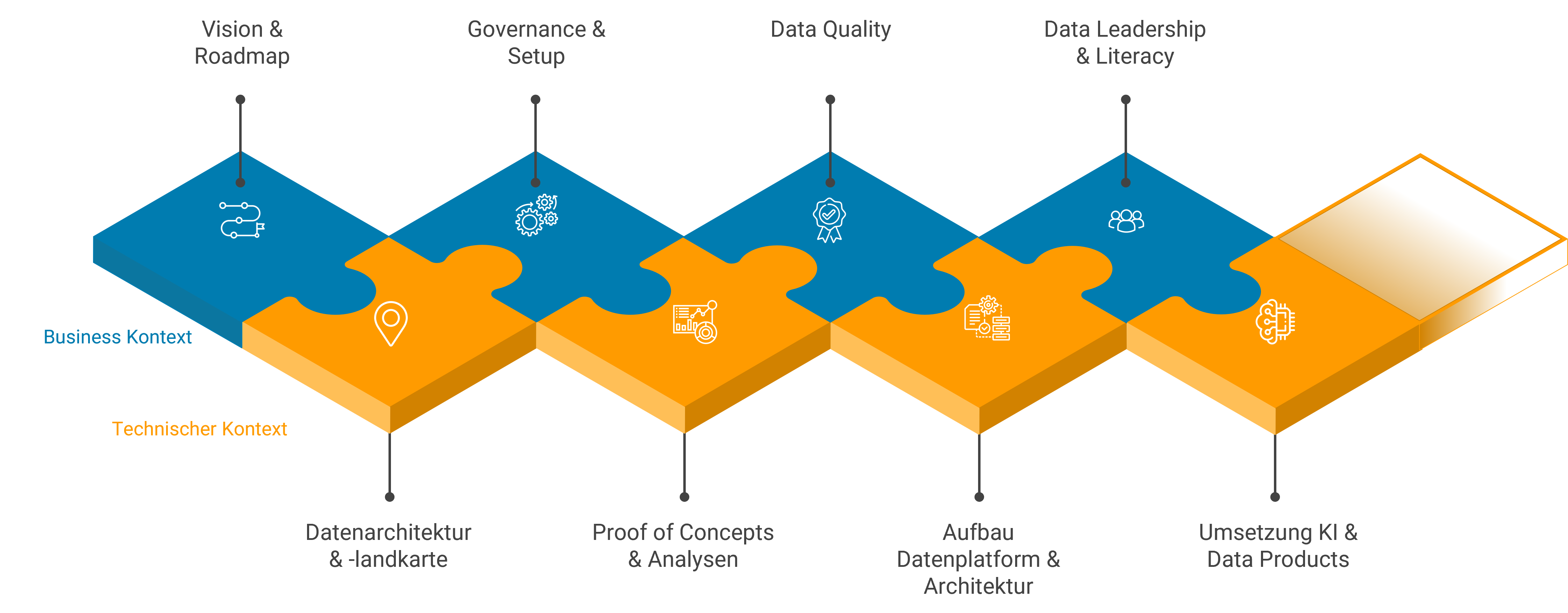
Die obere Grafik zeigt diese zwei Stränge als ineinandergreifende Puzzleteile: Oben der Business-Kontext mit Vision & Roadmap, Governance & Setup, Data Quality und Data Leadership & Literacy. Unten der technische Kontext mit Datenarchitektur & -landkarte, Proof of Concepts & Analysen, Aufbau Datenplattform & Architektur und Umsetzung KI & Data Products.
Das Strategie-Rad zeigt die sechs Dimensionen, die eine vollständige Datenstrategie abdecken muss: Vision & Ziele im Zentrum, umgeben von Data Architecture & Technology, Data Usage, Information Security, Governance & Quality sowie Culture & Literacy. In welcher Dimension Sie starten, hängt von Ihrer Maturitätsstufe ab.
Typische Ausgangssituationen, die wir antreffen:
- Stufe 1 – Excel & Bauchgefühl: Reports werden manuell erstellt, Daten liegen in Silos, Entscheidungen beruhen auf Erfahrung. Hier braucht es kein KI-Projekt, sondern erst mal eine Datenlandkarte und ein zentrales Reporting.
- Stufe 2 – Erste Reports, aber Insellösungen: Es gibt BI-Tools, aber jede Abteilung kocht ihr eigenes Süppchen. Verschiedene Wahrheiten, keine Single Source of Truth. Der nächste Schritt ist eine zentrale Datenplattform.
- Stufe 3 – Zentrales DWH, standardisierte KPIs: Die Grundlagen stehen, Reports laufen automatisiert. Jetzt lohnen sich erste Advanced-Analytics-Use-Cases – Forecasting, Anomalieerkennung, Segmentierung.
- Stufe 4 – Predictive & Prescriptive: Modelle laufen produktiv, Entscheidungen sind datengestützt. Der Fokus verschiebt sich auf Skalierung, Governance und den Aufbau interner Datenkompetenz.
Egal auf welcher Stufe Sie stehen: Der richtige nächste Schritt ist immer genau eine Stufe weiter – nicht drei auf einmal.
Das Substring-Vorgehen: Align → Plan → Build → Run
Unser Engagement Model beschreibt, wie wir Datenprojekte strukturieren – von der ersten Abstimmung bis zum laufenden Betrieb. Es ist bewusst kein starres Wasserfallmodell, sondern ein iterativer Prozess, bei dem jede Phase ein klares Ergebnis liefert.
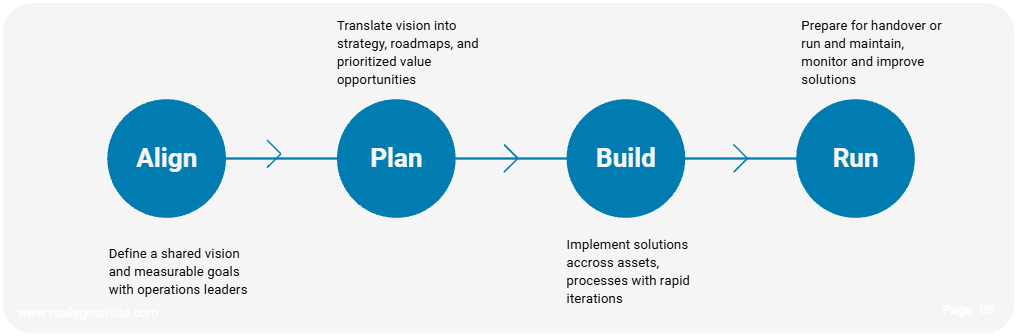
Phase 1: Align – Gemeinsame Vision definieren
Dauer: 1–3 Wochen
Bevor wir über Technologie, Datenmodelle oder Dashboards sprechen, steht die wichtigste Frage: Was wollen wir eigentlich erreichen?
In der Align-Phase arbeiten wir mit den Entscheidungsträgern Ihres Unternehmens – Geschäftsleitung, Fachbereiche, IT – an einer gemeinsamen Vision und messbaren Zielen. Was klingt wie ein weicher Einstieg, ist in der Praxis der entscheidende Erfolgsfaktor: Projekte, bei denen sich alle Stakeholder auf eine klare Richtung geeinigt haben, scheitern dramatisch seltener.
Was passiert konkret:
- Workshops mit Business- und IT-Stakeholdern zur Zieldefinition
- Aufnahme der bestehenden Datenlandschaft und Systeme
- Identifikation von 3–5 potenziellen Use Cases mit Business-Impact-Bewertung
- Auswahl des ersten Use Case für den Proof of Concept
Ergebnis: Ein abgestimmtes Zielbild und ein priorisierter Use Case, auf den sich alle committen – nicht ein 80-seitiges Strategiedokument, das niemand liest.
In vielen Fällen setzen wir in dieser Phase auch eine Datenmaturitätsanalyse ein, die in wenigen Tagen ein objektives Bild der Ausgangslage liefert.
Phase 2: Plan – Roadmap und priorisierte Opportunities
Dauer: 2–4 Wochen
Aus der Vision wird ein konkreter Plan. In der Plan-Phase übersetzen wir die abgestimmten Ziele in eine Roadmap mit realistischen Meilensteinen – technisch und organisatorisch.
Was passiert konkret:
- Definition der Datenarchitektur und Zielplattform
- Technologie-Evaluation (brauchen wir Microsoft Fabric, Databricks, eine klassische DWH-Lösung?)
- Aufwandschätzung und Ressourcenplanung
- Definition von Rollen: Wer ist Product Owner? Wer liefert Daten? Wer nimmt ab?
- Erstellung eines Sprint-Plans für die Build-Phase
Ergebnis: Eine umsetzbare Roadmap mit klaren Verantwortlichkeiten, Zeitrahmen und einem ersten Sprint-Backlog. Sie wissen jetzt, was es kostet, wie lange es dauert und was Sie dafür bekommen.
Phase 3: Build – Iterativ umsetzen, schnell liefern
Dauer: 2–6 Monate (je nach Umfang)
Die Build-Phase ist das Herzstück des Projekts – und hier wird es konkret. Wir arbeiten in Programmincrements von drei Monaten, unterteilt in zweiwöchige Sprints mit regelmässigem Feedback. Kein Big Bang nach 12 Monaten, sondern alle zwei Wochen ein sichtbares, testbares Ergebnis.
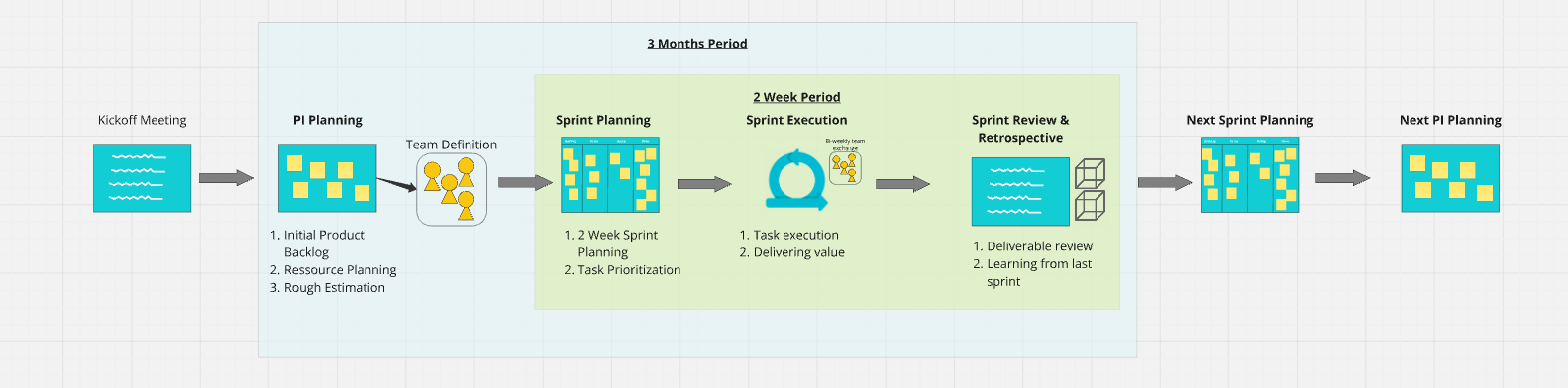
So sieht das im Alltag aus:
Kickoff Meeting → Das Projektteam kommt zusammen, Ziele und Rahmenbedingungen werden final abgestimmt.
PI Planning (Programmincrement-Planung):
- Initial Product Backlog erstellen
- Ressourcenplanung und Teamdefinition
- Grobe Aufwandschätzung für die nächsten drei Monate
Sprint-Zyklus (alle 2 Wochen):
- Sprint Planning – Tasks priorisieren und zuweisen
- Sprint Execution – Umsetzung und Wertlieferung
- Sprint Review & Retrospective – Ergebnisse prüfen, Learnings einarbeiten
Nach jedem Sprint gibt es ein funktionsfähiges Inkrement – sei es ein erstes Dashboard, eine angebundene Datenquelle, ein trainiertes Modell oder eine automatisierte Data Pipeline. Sie sehen jederzeit, wo das Projekt steht, und können bei Bedarf die Prioritäten anpassen.
Warum ein Product Owner auf Ihrer Seite entscheidend ist: Ein dedizierter Product Owner (oder eine vergleichbare Rolle) auf Kundenseite fungiert als zentrale Entscheidungsinstanz für Prioritäten, Umfang und Abnahme. Ohne diese Rolle fehlt dem Projekt sein wichtigstes Gegengewicht – die Business-Perspektive, die sicherstellt, dass wir nicht an der Realität vorbeibauen.
Typische Arbeitspakete in der Build-Phase:
- Datenintegration und ETL/ELT-Pipelines aufsetzen
- Datenqualitäts-Checks automatisieren
- Datenmodelle und KPI-Definitionen erarbeiten
- Dashboards, Reports oder ML-Modelle entwickeln
- User Acceptance Tests mit Fachbereichen durchführen
- Schulungen für Endanwender
Phase 4: Run – Betrieb, Übergabe, Weiterentwicklung
Dauer: laufend
Das Go-Live ist nicht das Ende, sondern der Anfang. In der Run-Phase sorgen wir für eine saubere Übergabe oder übernehmen den Betrieb – je nachdem, was zu Ihrer Organisation passt.
Drei Modelle für den Betrieb:
Modell A – Vollständige Übergabe: Wir schulen Ihr internes Team und übergeben Dokumentation, Code und Betriebshandbuch. Geeignet für Organisationen mit bestehender Datenkompetenz, die langfristig autark sein wollen.
Modell B – Managed Service: Wir betreiben die Lösung für Sie – Monitoring, Updates, Datenqualitätssicherung, Weiterentwicklung. Geeignet für Organisationen, die keine internen Data-Engineering-Ressourcen aufbauen wollen oder können.
Modell C – Hybrid: Ihr Team betreibt das Tagesgeschäft, wir unterstützen bei Erweiterungen, komplexen Analysen oder wenn neue Datenquellen angebunden werden. Das häufigste Modell in der Praxis.
Unabhängig vom Modell: Wir stellen sicher, dass die Lösung nicht nach sechs Monaten veraltet – durch Monitoring, regelmässige Reviews und eine klare Weiterentwicklungs-Roadmap.
Drei typische Einstiegs-Szenarien
Datenprojekte sehen je nach Branche und Ausgangslage sehr unterschiedlich aus. Hier drei Szenarien, die wir regelmässig begleiten:
Szenario A: Industrieunternehmen – "Wir haben Maschinenausfälle"
Ausgangslage: Ein Produktionsbetrieb verliert pro Jahr mehrere Hunderttausend Franken durch ungeplante Stillstände. Sensordaten sind vorhanden, werden aber nicht systematisch ausgewertet.
Typischer Weg:
- Align: Kritischste Anlage identifizieren, Ausfallkosten quantifizieren
- Plan: Sensorik prüfen, Datenarchitektur vom Shopfloor zum Dashboard designen
- Build: In einem Data Sprint Predictive-Maintenance-Modell als PoC aufbauen
- Run: Rollout auf weitere Anlagen, Integration in Wartungsplanung
Szenario B: Verkehrsunternehmen – "Wir haben Daten in 15 Systemen"
Ausgangslage: Ein ÖV-Betrieb hat Daten in Fahrplanung, Fahrzeuginstandhaltung, Ticketing, HR und Finanzen – aber keinen Gesamtüberblick. Jede Abteilung pflegt eigene Excel-Reports mit unterschiedlichen Definitionen.
Typischer Weg:
- Align: Kernfragen definieren (z.B. "Was kostet uns eine Buslinie wirklich?"), Datenlandkarte erstellen
- Plan: Zentrale Datenplattform evaluieren (z.B. Microsoft Fabric für Verkehrsunternehmen)
- Build: Erste Quellsysteme anbinden, standardisiertes KPI-Reporting aufbauen
- Run: Schrittweise weitere Fachbereiche onboarden, Self-Service BI ausrollen
Szenario C: Verwaltung / Bildung – "Wir wollen weg von Excel"
Ausgangslage: Eine öffentliche Verwaltung erstellt Quartalsberichte manuell in Excel. Die Daten kommen aus verschiedenen Fachapplikationen, die Konsolidierung dauert Tage und ist fehleranfällig.
Typischer Weg:
- Align: Informationsbedarf analysieren, Quick Wins identifizieren
- Plan: Leichtgewichtige Architektur definieren – oft reicht ein kleines Data Warehouse mit Power BI als Frontend
- Build: Automatisierte Datenanbindung, standardisierte Berichte, Schulung
- Run: Übergabe an internes Team mit klarer Dokumentation
Was es kostet – eine ehrliche Einordnung
Über Kosten spricht in unserer Branche niemand gern öffentlich. Verständlich – jedes Projekt ist anders. Deshalb sind die unten genannten Preise natürlich nur Richtwerte, die sich je nach Anforderung noch einmal ändern können. Trotzdem verdienen Sie eine realistische Grössenordnung, bevor Sie ein Budget freigeben:
Wovon hängt es ab? Die grössten Kostentreiber sind nicht die Tools (Cloud-Lizenzen sind meist überschaubar), sondern der Integrationsaufwand: Wie viele Quellsysteme müssen angebunden werden? Wie gut ist die Datenqualität? Wie viel Change Management braucht die Organisation?
Unser Rat: Starten Sie mit einem Data Sprint. CHF 20'000–50'000 für einen fokussierten PoC mit klarem Ergebnis – danach wissen Sie, ob sich die grössere Investition lohnt. Das ist deutlich billiger als ein 6-monatiges Projekt, das am Ende nicht das liefert, was die Organisation braucht.
Checkliste: Sind Sie bereit für ein Datenprojekt?
Sieben Fragen, die Sie sich stellen sollten, bevor Sie ein Projekt beauftragen. Nicht alle müssen mit "Ja" beantwortet werden – aber bei mehr als drei "Nein" lohnt sich ein Vorab-Assessment:
1. Gibt es eine konkrete Geschäftsfrage? "Datengetriebener werden" ist kein Use Case. "Warum haben wir 12% Ausschuss auf Linie 3?" schon.
2. Hat jemand aus dem Business Zeit und Interesse? Ein Sponsor aus dem Fachbereich – nicht nur IT – der das Ergebnis einfordert und nutzt.
3. Wissen Sie, wo Ihre wichtigsten Daten liegen? Nicht im Detail – aber zumindest welche Systeme die relevanten Informationen enthalten.
4. Sind die Daten digital und zugänglich? Handschriftliche Protokolle und PDF-Scans sind kein Ausschlusskriterium, erhöhen aber den Aufwand erheblich.
5. Gibt es ein realistisches Budget? Nicht für eine unternehmensweite Transformation – aber für einen fokussierten ersten Schritt.
6. Ist die Organisation bereit für Veränderung? Datengetrieben zu arbeiten bedeutet, Entscheidungsprozesse zu verändern. Gibt es die Offenheit dafür?
7. Ist klar, wer die Lösung nach Go-Live betreibt? Intern, extern oder hybrid – die Frage sollte vor Projektstart geklärt sein, nicht danach.
Bei mehr als drei "Nein" empfehlen wir, mit einer Datenmaturitätsanalyse zu starten – das schafft Klarheit in wenigen Tagen und liefert eine belastbare Grundlage für die nächste Budget-Diskussion.
Nächster Schritt
Der effizienteste Einstieg ist ein unverbindliches Erstgespräch: In 30–60 Minuten besprechen wir Ihre Ausgangslage, identifizieren mögliche Quick Wins und schätzen den Aufwand für einen ersten Data Sprint ein – ehrlich und ohne Verkaufsdruck.
Kontaktieren Sie uns – oder erfahren Sie mehr über unsere Arbeit in den Bereichen Data Consulting, BI & Data Platforms und Artificial Intelligence.